ChunkKV:基于语义块的KV缓存压缩技术
ArXiv ID: 2502.00299
作者: Xiang Liu, Zhenheng Tang, Peijie Dong, Zeyu Li, Yue Liu, Bo Li, Xuming Hu, Xiaowen Chu
机构: NVIDIA, Hong Kong University of Science and Technology
发布日期: 2025-02-01
会议: NeurIPS 2025
摘要
传统KV缓存压缩方法以单个token为单位进行重要性评估和淘汰,忽略了语言的语义连贯性。ChunkKV创新性地将语义块(semantic chunks)作为压缩的基本单元,保持完整的语言结构和上下文完整性。
系统通过三个核心技术实现高效压缩:
- 语义块识别:基于句法分析和语义边界检测,将token序列划分为有意义的语义单元
- 块级重要性评估:综合考虑块内token的平均注意力分数、位置信息和语义完整性
- 层级索引复用:跨层共享块索引,减少计算和存储开销
实验结果显示,ChunkKV在相同压缩率下比最先进的方法精度提升8.7%,同时实现了26.5%的吞吐量增益。该方法已被NVIDIA集成到KVPress库中,支持生产环境部署。
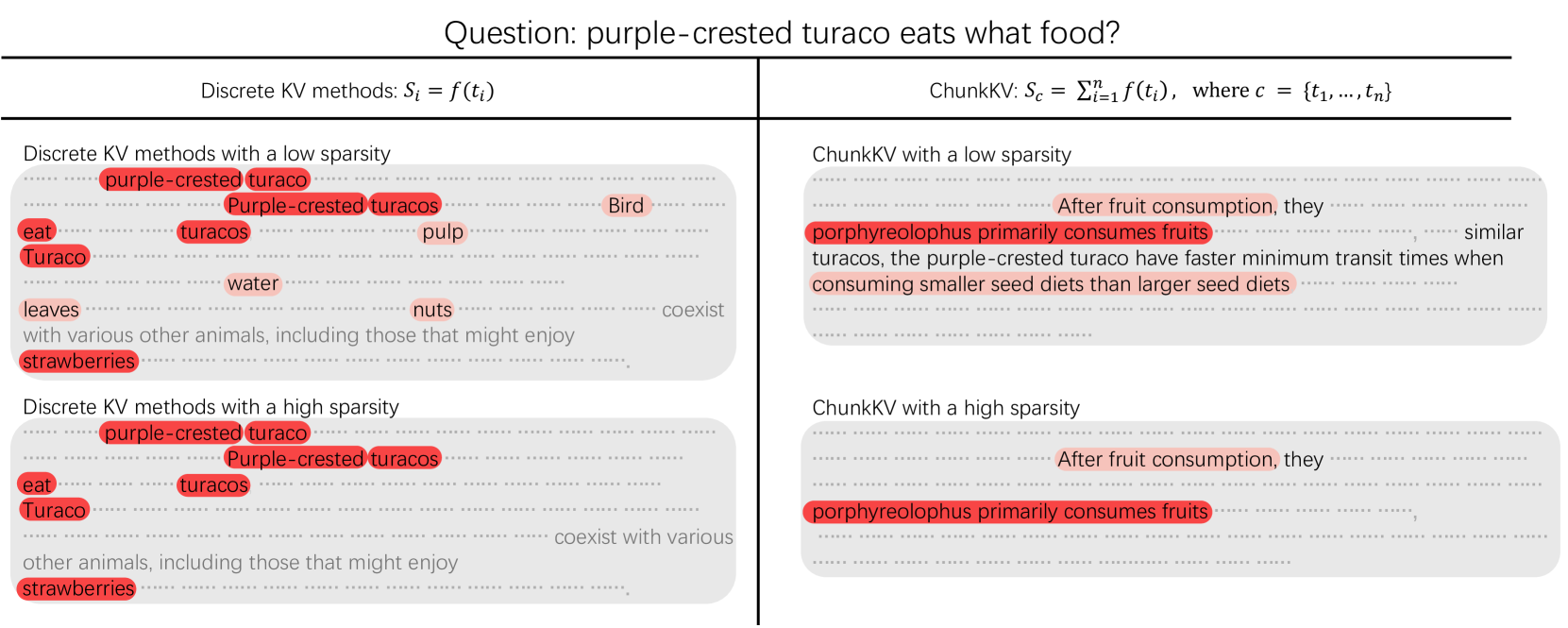
展示语义块识别、层级索引复用和压缩流程
核心贡献
- 语义块压缩范式:首次系统性地将语义块作为KV缓存压缩的基本单元,保持语言完整性
- 层级索引复用技术:跨Transformer层共享块索引,显著降低计算开销
- 精度提升:相同压缩率下精度提升8.7%,突破token级方法的精度瓶颈
- 吞吐量优化:26.5%的吞吐量提升,兼顾压缩率和推理效率
- 工业级实现:NVIDIA官方支持,集成到kvpress库
技术方案
ChunkKV分为三个阶段:
阶段1:语义块识别
- 使用轻量级句法分析器识别句子边界、短语结构
- 基于注意力模式检测语义边界(attention峰值和谷值)
- 自适应块大小:2-16个token,平衡粒度和效率
阶段2:块级重要性评估
- 聚合块内所有token的注意力分数
- 位置衰减:近期块权重更高
- 语义完整性奖励:完整句子/短语获得额外分数
阶段3:层级索引复用
- 第一层计算块索引和重要性分数
- 后续层复用索引,仅更新重要性权重
- 减少90%的块识别计算开销
性能评估
精度对比(8倍压缩,Llama-2-7B):
- H2O:准确率 52.3%
- StreamingLLM:准确率 48.7%
- SnapKV:准确率 61.5%
- PyramidKV:准确率 64.2%
- ChunkKV:准确率 69.8%(+8.7%)
吞吐量提升:
- 相对标准FlashAttention:1.26x
- 相对H2O:1.08x
- GPU利用率提升:15-20%
部署建议
集成方式:
- 使用NVIDIA kvpress库(推荐)
- HuggingFace Transformers插件
- vLLM自定义缓存策略
配置建议:
- 块大小范围:2-16 token
- 压缩率:根据任务选择2x-8x
- 索引复用:默认启用
适用场景:
- 长文档问答、摘要生成
- RAG应用
- 多轮对话(保持上下文连贯性)
个人评价
ChunkKV是KV缓存压缩领域的重要进展,将压缩单位从token提升到语义块,是思路上的创新。NVIDIA的支持保证了工业级质量。
优势:
- 精度领先:8.7%的精度提升非常显著
- 理论合理:语义块符合语言的自然结构
- 工程优化:索引复用大幅降低开销
- 工业支持:NVIDIA官方库,可靠性高
- NeurIPS接收:学术认可
应用价值:
- 适合对精度要求高的场景
- 与量化、稀疏注意力正交,可组合使用
- 未来可扩展到多模态(图像块、音频段)
评分: 4.4/5.0
代码仓库: GitHub