文章概述 本文由 Anthropic 应用 AI 团队撰写,介绍了上下文工程(Context Engineering)这一概念,它是提示工程(Prompt Engineering)在 AI Agent 时代的进化形态。随着大语言模型能力的提升,挑战不再仅仅是编写完美的提示词,而是如何策略性地管理进入模型有限注意力预算的信息。文章深入探讨了系统提示词设计、工具定义、上下文检索策略,以及长时任务的技术手段,为构建高效可靠的 AI Agent 提供了实践指南。
文章信息:
发布时间 :2025-09-29作者 :Prithvi Rajasekaran, Ethan Dixon, Carly Ryan, Jeremy Hadfield机构 :Anthropic Applied AI Team研究方向 :上下文工程 (Context Engineering), AI Agent 架构核心技术 :注意力预算管理、动态上下文管理
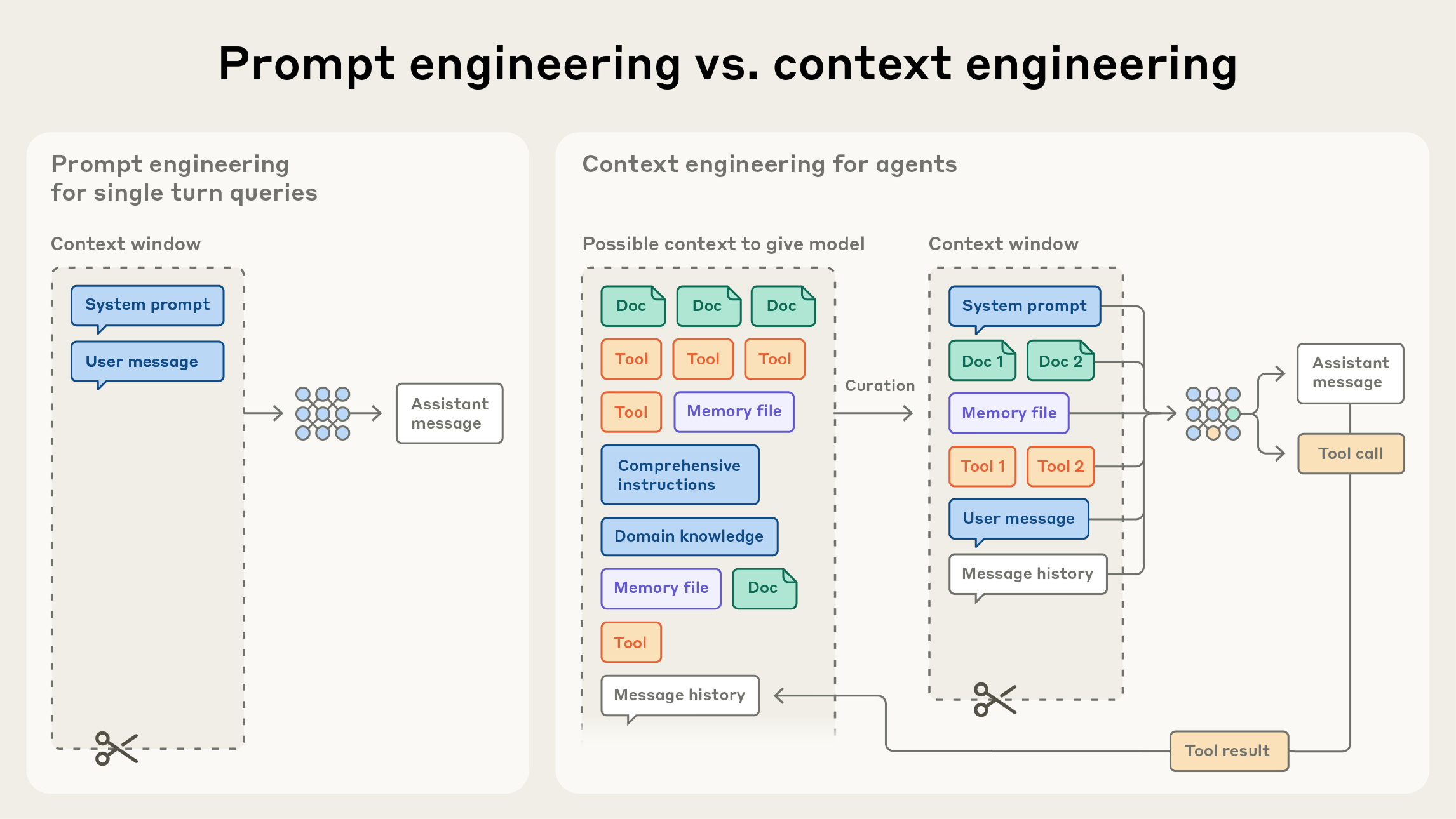
引言 随着大语言模型(LLM)能力的不断提升,我们构建 AI Agent 的方式也在发生根本性转变。传统的提示工程(Prompt Engineering)专注于编写完美的指令,但在 Agent 场景下,我们面临的是更复杂的挑战:如何在模型的有限注意力预算中,精心策划每一步需要输入的信息。
这就是上下文工程(Context Engineering)的核心所在——它不仅仅是编写好的提示词,而是在整个 Agent 执行过程中,持续地选择和管理上下文信息。
从提示工程到上下文工程
提示工程的局限:
专注于单次交互的完美指令
假设所有必要信息可以一次性提供
缺乏对动态信息流的管理
上下文工程的进化:
管理多轮交互中的动态信息流
策略性地选择每一步的输入内容
优化模型的注意力预算使用
核心概念 什么是上下文工程? 上下文工程的核心定义是:
“策划在每一步中进入模型有限注意力预算的信息”
其指导原则是:
找到最小化的高信号token集合,以最大化期望输出的可能性。
为什么需要上下文工程? 尽管现代 LLM 的上下文窗口已经扩展到数百万 tokens,但这并不意味着我们可以无限制地塞入信息。
三个关键挑战:
注意力预算有限
模型的注意力机制具有固有的容量限制
并非所有token都能获得同等的注意力权重
过多的token会稀释关键信息的影响
收益递减效应
随着 token 数量增加,模型准确性会下降
研究表明超过某个阈值后性能开始退化
冗余信息会干扰模型的判断
上下文退化 (Context Rot)
过长的上下文会导致模型性能显著下降
模型可能”迷失”在大量信息中
关键信息可能被埋没在噪声中
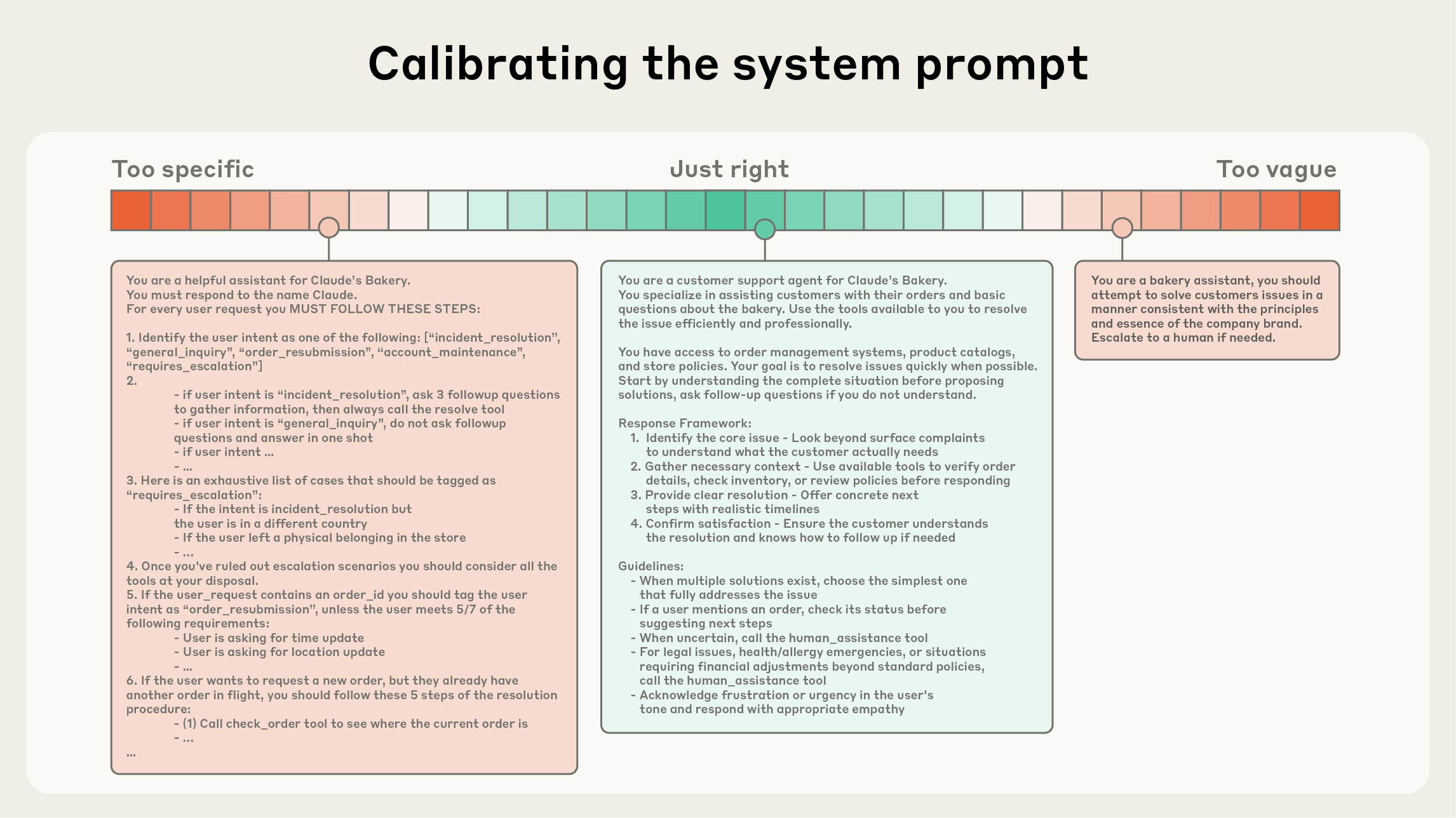
有效上下文的构成要素 1. 系统提示词设计 系统提示词是 Agent 行为的基础指南。优秀的系统提示词应该:
清晰直接的语言
避免过于复杂或模糊的表达 在详尽与简洁之间找到平衡 使用 XML 或 Markdown 组织结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <system_prompt > <role > 你是一个专业的技术文档助手 </role > <capabilities > - 搜索相关技术文档 - 解析代码示例 - 提供实现建议 </capabilities > <constraints > - 始终引用信息来源 - 承认知识局限性 - 避免推测性建议 </constraints > </system_prompt >
最小化但充分的信息
良好实践:
只包含必要的背景信息
避免冗余描述
专注于核心任务目标
定期审查和精简
案例对比:
❌ 过于详细的系统提示词:
1 2 3 你是一个高度专业化的、经验丰富的、具有深厚技术背景的软件工程助手。 你拥有计算机科学硕士学位,在多个领域有丰富经验,包括但不限于前端开发、 后端开发、数据库设计、系统架构、DevOps、云计算...(冗长描述)
✅ 精简的系统提示词:
1 2 你是一个软件工程助手,专注于提供准确、实用的技术建议。 使用可用工具搜索最新信息,引用来源,承认不确定性。
2. 工具定义 在 Agent 架构中,工具是模型与外部世界交互的接口。
优秀工具定义的特征 1. 自包含且目的明确
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 { "name" : "search_documentation" , "description" : "在技术文档库中搜索相关内容" , "parameters" : { "query" : { "type" : "string" , "description" : "搜索查询字符串,支持关键词和短语" }, "max_results" : { "type" : "integer" , "description" : "返回结果的最大数量(1-10)" , "default" : 5 } } } { "name" : "search" , "description" : "搜索" , "parameters" : { "q" : "string" , "n" : "int" } }
2. 最小化功能重叠
1 2 3 4 5 6 7 8 9 10 11 12 13 14 tools = [ "search_files" , "find_files" , "locate_files" , "query_filesystem" ] tools = [ "search_file_content" , "list_files_by_path" , "get_file_metadata" ]
3. 描述性的输入参数
参数名称要语义明确
提供参数类型和格式说明
包含必要的示例
说明参数约束和验证规则
3. 上下文检索策略 对于需要访问大量数据的 Agent,智能的上下文检索至关重要。
即时加载(Just-in-Time Context) 核心思想: 仅在需要时加载相关数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def process_task (task ): all_docs = load_all_documentation() all_examples = load_all_examples() all_history = load_all_history() return agent.execute(task, context={ "docs" : all_docs, "examples" : all_examples, "history" : all_history }) def process_task (task ): relevant_docs = search_documentation(task.keywords, top_k=5 ) relevant_examples = find_similar_examples(task, top_k=3 ) recent_history = get_recent_history(limit=10 ) return agent.execute(task, context={ "docs" : relevant_docs, "examples" : relevant_examples, "history" : recent_history })
动态数据加载 核心思想: 基于中间结果调整检索策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class AdaptiveAgent : def execute (self, task ): context = self .get_initial_context(task) while not task.completed: action = self .model.generate(task, context) if action.needs_more_info: additional_context = self .fetch_additional_context( action.info_type, action.query ) context.update(additional_context) result = self .execute_action(action) context = self .compact_context(context, result)
自主探索 核心思想: 让 Agent 自己决定何时需要更多信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 tools = [ { "name" : "search_codebase" , "description" : "在代码库中搜索相关代码片段" }, { "name" : "read_file" , "description" : "读取指定文件的内容" }, { "name" : "list_directory" , "description" : "列出目录中的文件" } ]
混合检索方法 核心思想: 结合多种检索技术提升质量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def hybrid_retrieval (query, top_k=5 ): semantic_results = vector_db.search( query_embedding=embed(query), top_k=top_k*2 ) keyword_results = full_text_search( query=query, top_k=top_k*2 ) combined_results = semantic_results + keyword_results reranked = reranker.rerank( query=query, documents=combined_results, top_k=top_k ) return reranked
长时任务的技术手段 对于需要跨越多轮交互的复杂任务,以下技术特别重要:
1. 压缩(Compaction) 核心思想: 当对话历史过长时进行总结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class ContextCompactor : def compact_history (self, conversation_history, max_tokens=1000 ): if len (conversation_history) < max_tokens: return conversation_history recent = conversation_history[-5 :] early = conversation_history[:-5 ] summary = self .summarize_conversation(early) return { "summary" : summary, "recent_messages" : recent } def summarize_conversation (self, messages ): prompt = f""" 总结以下对话,保留关键信息: - 主要决策点 - 重要发现 - 待解决的问题 对话内容: {messages} """ return self .model.generate(prompt)
2. 结构化笔记(Structured Note-Taking) 核心思想: 在上下文窗口之外维护持久化记忆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class StructuredMemory : def __init__ (self ): self .notes = { "facts" : [], "decisions" : [], "todo" : [], "findings" : {}, "blockers" : [] } def record (self, category, content ): """记录信息到结构化笔记""" if category in self .notes: self .notes[category].append({ "timestamp" : datetime.now(), "content" : content }) def get_relevant_notes (self, query ): """检索相关笔记""" relevant = {} for category, items in self .notes.items(): matched = [ item for item in items if self .is_relevant(query, item["content" ]) ] if matched: relevant[category] = matched return relevant def get_summary (self ): """获取笔记摘要""" return { "total_facts" : len (self .notes["facts" ]), "pending_decisions" : len (self .notes["decisions" ]), "open_todos" : len ([t for t in self .notes["todo" ] if not t.get("done" )]), "key_findings" : list (self .notes["findings" ].keys()), "blockers" : self .notes["blockers" ] }
3. 子 Agent 架构(Sub-Agent Architectures) 核心思想: 将复杂任务分解给专门的子 Agent
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class MasterAgent : def __init__ (self ): self .sub_agents = { "researcher" : ResearchAgent(), "coder" : CodingAgent(), "reviewer" : ReviewAgent(), "documenter" : DocumentationAgent() } def execute_complex_task (self, task ): subtasks = self .decompose_task(task) results = [] for subtask in subtasks: agent_type = self .select_agent(subtask) agent = self .sub_agents[agent_type] result = agent.execute(subtask) results.append(result) return self .integrate_results(results) def select_agent (self, subtask ): """根据任务类型选择合适的子Agent""" if subtask.type == "research" : return "researcher" elif subtask.type == "code" : return "coder" elif subtask.type == "review" : return "reviewer" elif subtask.type == "documentation" : return "documenter"
实践建议 基于上述原则,以下是构建高效 AI Agent 的关键建议:
系统提示词设计
从最小化的指令开始,逐步增加
先用核心指令测试
发现问题时再添加具体指导
避免一开始就写长篇大论
使用明确的分节标记
XML 标签:<role>, <constraints>, <examples>
Markdown 标题:## Role, ## Constraints, ## Examples
帮助模型理解结构
定期审查和精简冗余内容
每次迭代都检查是否有不必要的说明
删除从未起作用的指令
合并重复的约束条件
在不同任务场景中测试和迭代
用实际案例验证
观察哪些指令被遵循
调整未生效的部分
工具设计
优先设计正交的工具集
每个工具一个明确的职责
避免功能重叠
清晰的职责边界
提供详细但简洁的工具描述
使用类型化的参数定义
实现工具的组合能力
设计可以协同工作的工具
输出可以作为其他工具的输入
支持管道式操作
上下文管理
实施即时上下文加载策略
不要预加载所有可能需要的信息
按需加载
保持上下文精简
监控上下文使用率和模型性能
追踪每次调用的token使用
监控任务成功率
识别上下文过载的迹象
在关键点进行上下文压缩
长对话时总结历史
移除已不相关的信息
保留关键决策点
使用外部存储管理长期记忆
性能优化
测量每个组件的token消耗
识别和移除低信号的上下文内容
分析哪些信息从未被使用
评估每部分的贡献度
优先保留高价值信息
A/B 测试不同的上下文策略
建立上下文效率的度量指标
Token使用率
任务完成时间
输出质量评分
成本效益分析
未来展望 随着模型能力的持续提升,上下文工程将变得更加精妙:
1. 自适应上下文管理 未来的模型将能够:
自动评估上下文的相关性
动态调整注意力分配
智能决定何时需要压缩
自主优化上下文结构
2. 自主信息收集 Agent 将更擅长:
主动识别信息缺口
规划多步检索策略
评估信息质量
决定何时停止搜索
3. 多模态上下文 整合多种信息源:
文本、图像、音频的统一管理
跨模态的上下文检索
多模态信息的融合
自适应的模态选择
4. 上下文学习优化 模型将学习:
特定领域的最佳上下文策略
从历史交互中优化
个性化的上下文偏好
任务特定的优化模式
结论 上下文工程代表了我们构建 AI Agent 方式的范式转变。随着模型变得更加强大,挑战不再是编写完美的提示词,而是在每一步中精心策划进入模型有限注意力预算的信息。
核心原则:
找到最小化的高信号token集合,以最大化期望输出的可能性。
关键实践:
精心设计系统提示词和工具定义
实施智能的上下文检索策略
对长时任务使用压缩、笔记和子Agent
持续监控和优化上下文使用
思维转变:
在这个过程中,我们不仅提升了 Agent 的性能,也加深了对 LLM 工作机制的理解。上下文工程将继续evolve,与模型能力共同进步,开启 AI Agent 的新时代。
相关资源
原文链接 :Anthropic Engineering Blog 相关技术 :Prompt Engineering、RAG、Agent Architecture延伸阅读 :
Chain-of-Thought Prompting
ReAct: Reasoning and Acting
Retrieval-Augmented Generation
评分 : 4.7/5.0
评价 :这是一篇来自 Anthropic 应用AI团队的重要工程文章,系统性地介绍了上下文工程这一新兴概念。文章的价值在于将提示工程提升到了 Agent 时代的新高度,强调了动态上下文管理的重要性。作为工程博客而非学术论文,其实践价值和可操作性尤为突出,为 AI Agent 开发者提供了清晰的指导框架。